[리펙토링]인덱스로 쿼리 실행시간 줄이기
내가 하고 있는 프로젝트는 소셜로그인을 진행하고 클라이언트로 Json 을 넘겨주는 과정에서 단순 성공/실패 만의 정보를 넘겨주는 것이 아니라, 굉장히 많은 정보를 넘겨주고 있다.
실행 로직은 잠시 설명해보자면,
1. 깃허브 소셜로그인을 진행한다.
2. 넘겨받은 깃허브 id 로 우리 데이터베이스를 순회하며, 해당 깃허브 아이디를 가진 유저가 있는지 찾는다.
3. 있다면 엑세스/리프레시 토큰을 반환하고, 없다면 빈 값으로 응답한다.
데이터베이스를 mySQL 을 사용하고 있는데, 일반적으로 인덱스를 생성하지 않았을 때에는 primary 로 지정해두었던 id 값이 자동으로 인덱스 적용되어 검색할 때 사용하곤 한다. 그치만 마음에 걸렸던 부분은 나는 member_id 로 검색하는 것이 아니라 String 값은 github_id 로 맞는 유저를 찾고 있다는 점이었다!
이전 학기에 수강한 데이터베이스 시간에 배웠던 인덱스 만들기가 생각나서, 이 프로젝트에 도입시켜볼까? 싶어 리펙토링을 진행하게되었다.
인덱스를 만들기에 앞서, JPA 가 날리는 쿼리문이 어떻게 생겼는지 부터 파악해 보았다

이렇게 생긴 쿼리문을 날린다. where 절을 보면 github_id 와 status 로 유저를 찾고있다는 것을 파악했다. 그래서 github_id 와 status 로 인덱스를 만들어야겠다고 생각했다.
먼저 인덱스를 만들기 전에, workbench 에서 쿼리 실행계획도 혹시 몰라 살펴보았다.

역시나, Full Table Scan 을 하고 있었다.
그래서 후두다닥 인덱스를 만들어 보았다

어떤 인덱스가 더 효율적일지 잘 모르겠어서.. 일단은 두개 다 만들어 보았다.
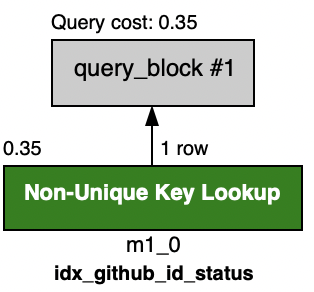
그리고 다시 쿼리실행 계획을 살펴보았더니, idx_github_id_status 인덱스가 적용된 것을 확인할 수 있었다.
워크벤치가 판단하기에 status 먼저 인덱싱하는 것보다 github_id 가 더 효율적인가보다...ㅎㅎ
성능 개선을 했으면, 실제로 얼마나 성능이 개선되었는지를 확인해봐야할 것 아닌가!! 그래서 postman 으로 열~~심히 요청을 날려보았는데 큰 시간 차이를 느끼지 못했다. 그래서 확실히 성능을 확인할 수 있도록 테스트 데이터를 넣어봐야겠다고 생각했다.
수업시간에 배웠던,, python 코드를 이용해 더미 데이터를 삽입해보았다!

총 6백만개의 데이터를 삽입하였고, 랜덤한 "막"데이터를 넣어두었다. 그리고 맨 마지막엔 소셜로그인으로 확인해봐야 해서, 실제 내 데이터도 하나 추가해주었다.
그리고 postman 으로 실행시간을 확인해보았더니, 다음과 같았다!
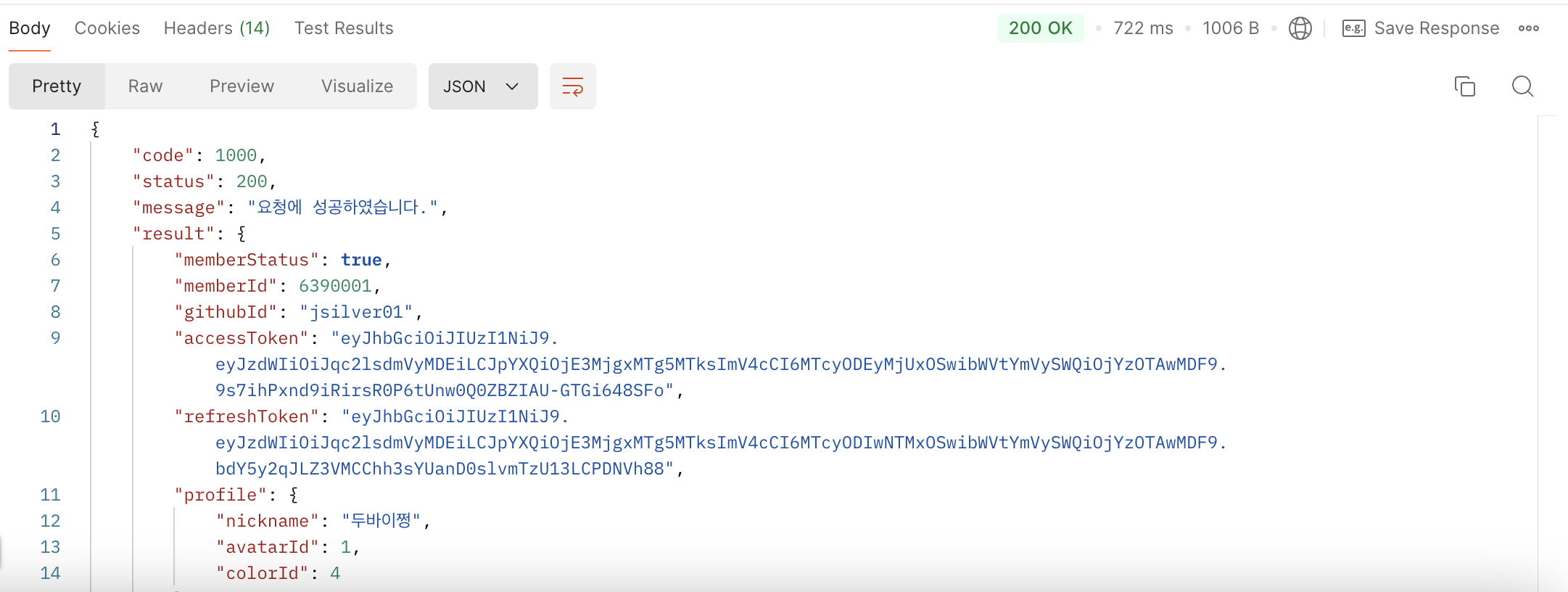
722ms 가 걸린 것을 확인할 수 있었다. 이게 얼마나 빨라진 건지 감이 안오니! 인덱스를 삭제하고 비교해보겠다~

먼저 기존에 만들어놓았던 인덱스를 삭제하고 다시 쿼리 실행계획을 살펴보면 다음과 같다.

다시 새빨간.. full table scan 으로 돌아간 것을 확인할 수 있다.

포스트맨으로 확인해보면 동일한 응답 결과를 3.36s 가 걸려서 반환하는 것을 확인할 수 있다. 이렇게보면 엄~~~청 큰 차이가 생긴다!
이제 서버 배포 준비 갈 완료~
끝!